RustにおけるOwnershipの仕組み
前回に引き続き、Mozillaイチオシの言語であるRustを触ってみる。今日はメモリ管理の仕組みとしての「Ownership」に着目する。
ちなみに、今日書く内容はRust Guideの17章、OwnershipのGuide、PointerのGuideをつまみ食いしながら適当にまとめたものなので、原文読んでもらっても良い。
メモリ管理について
まずは背景として、メモリ管理の必要性について考えてみる。
一般に、計算機上で動くソフトウェアというのはデータをメモリ上に次々に確保して様々な計算等を行っていく訳だけど、メモリというのは有限の大きさしか持たない為にデータの追加ばかりしていく訳にも行かなくて、使わなくなった領域を次々に解放して再利用しなければならなくなる。
こういった事を考えると、メモリ解放の機構を言語に組み込む必要性があると分かる。
メモリに確保されるデータの種類
メモリに確保されるデータには、大別すると次の3種類がある。
- ソフトウェア実行中はずっと残る静的なデータ
- プロシージャ呼び出し時に確保され、プロシージャを抜けると解放されるスタック上のデータ
- ソフトウェア実行時に動的に確保されるデータ(ここで確保される領域をヒープメモリと呼ぶ)
メモリの解放という文脈でこれらのデータを考えると、1の静的なデータはずっと残るものなので解放されないし、2のスタック上のデータは勝手に解放されるので気にしなくて良いのだけど、3の動的に確保されるデータをどう扱うかが問題になってくる。
c言語では、mallocやfreeによってユーザーが責任を持ってメモリの確保と解放を行うことが求められたけど、メモリリークや不正なメモリへのアクセス等が起きやすく大きな問題を抱えていた。
一方、近年の多くの言語では Garbage Collection(GC) の機構を組み込みで持つことでユーザーをメモリ管理の複雑さ・煩雑さから解放したが、 GC 実行時にストップザワールドが起こる等のデメリットもあった。
そこで、Rustは「Ownership」という考え方を導入することで、メモリリークの危険性を抑えながらパフォーマンス上の問題を解決することを目指した。
Ownership
動的にメモリを確保する際、例えばc言語では
{
int *x = malloc(sizeof(int));
// we can now do stuff with our handle x
*x = 5;
free(x);
}
の様な書き方をする。同様の事が、Rustにおいては
{
let x = box 5i;
}
という記述で表現できる。ポイントは、この記述できちんとメモリの確保と解放が表現出来ている事だ。
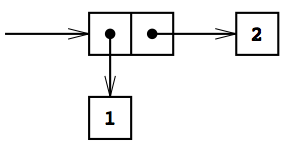
box というキーワードによって 5i という値がヒープ上に動的に確保され、その参照がxへbindされている。このxがownershipを持っていて、xがscopeから外れる(xを含むブロックを抜ける)時にメモリの解放が行われる。
この様に変数にownershipを持たせる事で、メモリの解放が必ず行われる事を保証できる様になる。
ownershipは移動させることもできて、例えばBox型の値(boxキーワードでヒープに確保した値への参照)を引数として関数を呼び出した場合には、ownershipはその関数内の変数numに移る。
fn main() { let x = box 5i; add_one(x); } fn add_one(mut num: Box<int>) { *num += 1; }
ただし気をつけなければならないのは、ownershipを移すと、ownershipを失った変数からは元の値へアクセス出来なくなる事である。上記の例であれば、add_one(x)呼び出しの後にxを使おうとするとエラーが出る。
fn main() { let x = box 5i; add_one(x); println!("{}", x); // error!!!!! } fn add_one(mut num: Box<int>) { *num += 1; }
この問題を避けるために、例えば関数から返り値を使うといった方法が考えられる。
fn main() { let x = box 5i; let y = add_one(x); println!("{}", y); } fn add_one(num: Box<int>) -> int { *num + 1; } //注: これはあくまで例で、あまり良い方法では無い。
ただし、今回の例ではnumの所有権は一時的なものであれば良く、返り値という形ですぐにまたmainのyに戻されている。こういった一時的な所有権というシチュエーションは良くあるものであり、上記の例よりもBorrowingという仕組みを使う方が推奨されている。
Borrowing
Borrowingとは、ownershipは移さずに値への参照を可能にする機構である。&キーワードで値への参照を作ると、それは値をborrowingする為のpointerとなる。例えば、ownershipを移すことで実現していた上記の例は、以下のコードに書き直せる。
fn main() { let x = box 5i; println!("{}", add_one(&*x)); } fn add_one(num: &int) -> int { *num + 1 }
呼び出し方がちょっとややこしくなってるけど、 *x で5iという値を意味していて、さらにその値をborrowingするために&キーワードで参照を作っている。
xのownershipは移動しない為、何度でもxの値を使用できる。
fn main() { let x = box 5i; println!("{}", add_one(&*x)); println!("{}", add_one(&*x)); // 何度でもxを使える!! println!("{}", add_one(&*x)); // 何度でもxを使える!! }
良い感じ。
mutableなborrowing
mutableなborrowingというのも一応出来て、&mutキーワードを使ってmutableな参照を作れば良い。ただし、もともとの値がmutableでないといけない。
fn main() { let mut x = box 5i; add_one(&mut *x); println!("{}", x); // xの値はborrowingされただけで移動してないから使える!! } fn add_one(num: &mut int) { *num += 1 }
mutや&mutや*の様なキーワードが入り乱れる事になるのでちょっとつらい感じになる。
Owner、およびBorrowerの権限について
Rustにおいては、ownerやborowerにはそれぞれ独自の権限がある。ownerは、次の3つの権限を持つ。
owner の権限
- リソースがいつ解放されるかを制御出来る。
- リソースを immutable な形で多くの borrower に貸し与えることが出来る。
- リソースを mutable な形で1つの borrower に貸し与えることが出来る。
ただし、これは次の2つの制約の存在も意味する。
owner の制約
- 既に誰かに貸し与えたリソースを変更したり、mutable な形で別の誰かに貸し与えたりする事は出来ない。
- 既に誰かに mutable な形で貸し与えたリソースは、アクセスすることが出来ない。
基本的に、変更によって変な競合が起きる可能性のある事は禁止されてるっぽい。
また、borrowerには次の権限がある。
- borrowがimmutableなら、リソースの読み取りが出来る。
- borrowがmutableなら、リソースの読み書きが出来る。
- 他の誰かにリソースを貸し与える事が出来る。
ただし、borrowerにも重要な制約があり、
「他の誰かにリソースを貸し与えたら、自分のborrow backの前に貸し与えた分を borrow backしてもらわなければならない」
らしい。この制約が守られないと、例えばownerのスコープが終了してメモリが解放され、不正な値となった領域にborrowerがアクセスする、といった危険な事が起きてしまう。そういった意味で、大事な制約となっている。
所感
Ownershipについて調べてみて、Cなんかと比べて一番便利なのはヒープ上に確保した値をプロシージャで安心して返せることなのかもなーと思った(返り値のownerが明確であれば、メモリの解放を保証出来るから)。
正直、Cでバリバリコーディング出来るとかでは全然無いんだけど、解放が保証されるか分からないポインタを使うとか想像するだけで怖すぎるなーとは思う。
で、C++におけるメモリ管理のお作法がちょっと気になったのでGoogle C++スタイルガイド 日本語訳とかいうのを見てみたら、現代的なC++コーディングではスマートポインタという解放が保証された機構を使うものらしい事を知った。
基本的には所有権の移動が無い scoped_ptr を使って、どうしても共有の必要性が出てきたら(参照カウントを組み込んだ) shared_ptr を使うと。なるほど。
割とRustと似たような事をやるっぽい。
Rustに入門してみる
今日は、Rustに入門してみる。
Rustは、Mozillaの開発したプログラミング言語である。公式サイトでは"high-level, bare-metal programming"を謳っており、高い抽象度を保ちながら低いレイヤーのコントロール(具体的にはユーザーによるメモリ管理等)が可能らしい。
近年出てきた言語の内、高い抽象度とハイパフォーマンスの両立を強みにしていた言語としてはGo言語が真っ先に思い浮かぶ。ただ、GoにおいてはGCを採用していた事を考えると、手動でメモリ管理が可能なRustはさらに低レイヤーを担当する事を目指してるようだ。
MozillaとしてはCやC++に置き換わりたい様だし、そういった立ち位置を目指す言語に興味が湧いたのでちょっと触ってみた。
とりあえず、公式サイトのGuideの手順を順番に試してみる。
1. RustをMacにインストール
公式サイトに従って、curlでschellscriptダウンロードして実行する。
curl -s https://static.rust-lang.org/rustup.sh | sudo sh
rustとcargoのinstallerのダウンロードが始まって、だいたい5~10分程でインストールが完了する。
ちなみに、installされたRustのversionはrustc --versionで確認出来て、14/12/06時点では以下だった。
rustc 0.13.0-nightly (6f4c11be3 2014-12-05 20:23:10 +0000)
まだ1.0前のアルファ版なのでアップデートはあるらしく、定期的にcurl -s https://static.rust-lang.org/rustup.sh | sudo shでアップデートしてねって感じらしい。
2. Hello worldしてみる。
とりあえずHello world。main.rsファイルにmain関数を定義。
// main.rs fn main() { println!("Hello, world!"); }
rustcコマンドでコンパイル。そして実行
$ ls main.rs $ rustc main.rs $ ls main main.rs $ ./main Hello, world!
ちゃんとHello worldが出力された。やったぜ!!
main.rsのコードについて
割と見たまんまの解釈で良くて、fnキーワードと波括弧({})で囲んだブロックでmain関数を定義してる。main関数は特別な関数で、生成したバイナリの実行時にはmain関数の中身が実行される(この辺はCとかと一緒)。
println!ってのが実はただの関数じゃなくて、Macroらしい。ビックリマーク(!)ついてればMacroらしいけど、まだ序盤だからって事で理由は教えてくれなかった。そもそもRustにおけるMacroってのが何を指してるのかはまだ分からない。
後、indentはスペース4つって指定されてた。
3. Cargoを使う。
CargoというのはRustのプロジェクトを管理する為のツールで、具体的にはRustのコードのビルド、依存ライブラリのダウンロード、依存ライブラリのビルドの3つの仕事を行うらしい。そこそこの規模のプログラムを書くならCargoを使うべきとの事。
まあ今は練習なので、先ほど書いたmain.rsをCargoプロジェクトにしてみる。まずは、srcディレクトリを作ってそこにmain.rsを移動する。cargoでは、srcディレクトリにコードを置くのが規約らしい。
$ mkdir src $ mv main.rs src $ rm main
次に、configuration fileであるCargo.tomlを生成。TOMLって見た事なかったんだけど、INIの進化版みたいな感じらしい。
// Cargo.toml [package] name = "hello_world" version = "0.0.1" authors = [ "south37 <sout37777@gmail.com>" ] [[bin]] name = "hello_world"
Cargo.tomlにはプロジェクト名、version, author名なんかを書く。そして、buildコマンドでビルド。
$ cargo build Compiling hello_world v0.0.1 (file:///Users/<ユーザー名>/Documents/programs/rust/hello_world) $ ./target/hello_world Hello, world!
これで、targeフォルダ以下に実行ファイル(hello_world)が生成される。良い感じ!!
ちなみに、cargo build実行後にはCargo.lockファイルが生成される。中身は
[root] name = "hello_world" version = "0.0.1"
で、あまり大した内容になってないけど、依存ライブラリ等があればここに書き込まれていくらしい。
lockって拡張子がGemfile.lockを彷彿とさせるんだけど、どちらも元ネタは同じだったりするのだろうか?gemはまさに依存関係管理ツールだし。
4. 変数へのbinding
Rustでは、letキーワードを使って変数への値のbindingを行う。Rustは静的型付け言語であり、型付けを行わなければならない。
let x: int = 5;
型の表記が無いとエラーが出る。
let x = 5;
$ rustc practice.rs practice.rs:2:9: 2:14 error: cannot determine a type for this local variable: cannot determine the type of this integer; add a suffix to specify the type explicitly [E0102] practice.rs:2 let x = 5; ^~~~~ error: aborting due to previous error
ただ、Rustは型推論をサポートしている為、型が自明であれば問題は無い。例えば、上記の例ではiをつけて数値がintegerである事を示してあれば大丈夫。
let x = 5i; // 5の後ろのiがintegerの値であることを示している。
デフォルトでは変数はimmutableであり、書き換えることは出来ない。
let x = 5i;
x = 10i;
$ rustc practice.rs practice.rs:3:5: 3:12 error: re-assignment of immutable variable `x` practice.rs:3 x = 10i; ^~~~~~~
mutableな変数を用意したければ、mutキーワードを使う。
let mut x = 5i; x = 10i;
immutableがデフォルトってのは個人的にはとても好ましい。公式サイトによれば、安全性を考慮した結果らしい。
5. if構文
Rustのifを使った条件分岐は見たまんま。自然に理解できる。
let x = 5i; if x == 5i { println!("x is five!"); } else { println!("x is not five :("); }
ただ、Rustにおいては構文のほとんどが式(expression)であり、値を返すため、if式も下みたいな使い方ができる。
let x = 5i; let y = if x == 5i { 10i } else { 15i };
良い感じ。
Rustにおける構文の内、値を返さない文(statement)は2種類しか無いらしい。一つは変数のbindingで、下記の表記は出来ない。
let x = (let y = 5i); // expected identifier, found keyword `let`
もう一つはexpression statementと呼ばれる構文で、セミコロン(;)をつけることでexpressionがstatementに変換される。(逆に言えば、デフォルトではrustの構文は全てがexpression)。
例えば、if式の中でセミコロン(;)を使うと値が返されない(より正しく言うとunitと呼ばれる特別な値が返される)。その為、以下のセミコロンを用いたif構文の結果を変数にbindingしようとするとエラーが出る。
let x = 5i; let y: int = if x == 5i { 10i; } else { 15i; };
$ rustc practice.rs practice.rs:4:18: 4:51 error: mismatched types: expected `int`, found `()` (expected int, found ()) practice.rs:4 let y: int = if x == 5i { 10i; } else { 15i; };
終わりが見えてこない
まだ構文の本当に基礎っぽいとこしか触れてないけど、終わりが見えてこないので今日はここまで...
本当はRustのメモリ管理に興味があって、ownershipとかborrowingとかみたいな現代的なメモリ管理について学べそうで興味を持ったんだけど、このペースだとたどり着けないのでまた今度にする。
ownershipは、まだあんま分かってないけどスコープを抜けるときに確保したメモリが解放される仕組みっぽい。それだけだとスタックと変わら無いんじゃないかと思うけど、別のスコープにownershipを移す事ができたり(その場合は元のスコープの所有では無くなる)、別のスコープに所有権を貸し与えたり出来るので、常に1つのスコープに所有されつつ、そのスコープが終了すればメモリの解放が行われる事を保証出来るらしい。
まだ自分でコード書いて試してみてないからアレだけど、説明だけ読んだ感じだとすごく良い仕組みのように感じる。
参考
Ownershipとかについては、このページで紹介されてて興味を持った。
こちらは所有権の移動(move)の説明。
おめでたい話
今日は、プライベートなお話を書く。とてもおめでたいお話。
背景: VOYAGE GROUPでのインターンとリレーブログ
実はこのブログは焼き肉ブログというはてなグループに所属していて、グループ内ではメンバー同士で1日交代でブログを書いていってる。メンバーは皆去年の夏に同じインターン(VOYAGE GROUPのTreasure)に参加した仲間で、ブログを書く習慣をつけたりお互いに知見を交換しあったりする為にリレーブログを始めた。何人かは地方にいる為にそんなに頻繁には会えないんだけど、東京に来る機会があった時は皆で焼き肉を食べに行ったりして、何だかんだで1年以上の付き合いになってた。
そんな中、メンバーの一人であるdorivenが結婚する事になり、まさに今日、都合がついた僕, ism1000ch, moguranosenshiの3人で結婚式に出席してきた。
やっぱり色々思うところはあったので、簡単にだけどまとめてみたいと思う。
続きを読む7つの言語 7つの世界を読んだ
「7つの言語 7つの世界」という本を図書館から借りてきて読んだ。この本では、異なるパラダイムをサポートする7つの言語について、シンプルながら本質を捉えた説明がなされていた。もともと色んな考え方を知るのは好きな方なので、めちゃめちゃ楽しんで読めた。
取り上げられていた7つの言語
筆者が選んだのは、Ruby, Io, Prolog, Scala, Erlang, Clojure, Haskellの7つの言語だった。筆者としては、オブジェクト指向が圧倒的に広まってる中、関数型の考え方や並行処理に対する優れたアプローチを紹介したいという意図があったようだ。
7つの言語のうちRuby, Scala, Haskellについてはそこそこ触った事はあったんだけど、他は全然知らない言語だった。特にIoについては名前すら知らなかったので、この本のお陰で出会えて良かったと思う。
ClojureはLisp族だし置いとくとして、Io, Prolog, Erlangみたいな全然触れた事が無かった言語についてまとめてみる。
Io
Ioはプロトタイプベースのオブジェクト指向言語で、そういった点ではJavaScriptの仲間になる。プロトタイプベースのアプローチでは、オブジェクトの振る舞いをクラスによって表現するのでは無く、プロトタイプとなるオブジェクトを指定することで表現する。JavaScriptのプロトタイプは、関数をコンストラクタにして、コンストラクタのprototypeプロパティにオブジェクトを指定して、そのプロトタイプを持つオブジェクトをnew演算子で生成して...みたいにめちゃめちゃ分かりにくい設計になってるんだけど、Ioはかなりシンプルな文法でプロトタイプベースのオブジェクト生成が行えるので、分かりやすさという意味でめちゃめちゃ魅力的だった。
Ioでは、オブジェクトを生成する際は基本的には既存のオブジェクトをCloneすれば良い。
Ferrari := Car clone // CarオブジェクトをプロトタイプとしたFerrariオブジェクトを生成
cloneがCarオブジェクトに対するメッセージになってるのもポイントで、Ioでは特殊な構文というものを用意せず、徹頭徹尾メッセージングによってプログラムを構築する事になる。この辺は以下の記事がよくまとまってると思う。
るびま: Rubyist のための他言語探訪 【第 3 回】 Io
一貫性がある設計というのは自分としてはものすごく好ましい事で、理解しやすいし興味深かった。
並行処理を言語の基盤レベルでサポートしてるのも特徴的で、Ioではコルーチン、アクター、フューチャといった機能を簡単に使うことが出来る。コルーチンはメソッドの処理中にいったん処理を抜けて他のメソッドに処理を譲る仕組みで、Ioにおいてはメッセージの非同期呼び出しとyieldメッセージでコルーチンを実現することが出来る。
アクターは分散処理を実行する単位となる存在で、Ioにおいては独自のThreadを持つオブジェクトとして表現される。アクターの生成はものすごく簡単で、オブジェクトに非同期メッセージを送るだけで良い。
1 obj1 := Object clone 2 obj1 name := "obj1" 3 obj1 test := method( 4 for(n, 1, 3, 5 n print 6 ": " print 7 name println 8 yield 9 ) 10 ) 11 12 obj2 := obj1 clone 13 obj2 name := "obj2" 14 15 obj2 @@test; obj1 @@test 16 Coroutine currentCoroutine pause
上記の例では、obj1とobj2に@@testという非同期メッセージを送って、アクターとして動作させている(メッセージの先頭に@@をつけると非同期呼び出しになる)。
testメソッドの中にyieldメッセージが含まれているため、この時点で処理を別のアクターに移すことになる。これはまさにコルーチンとしての振る舞いである。
上記のコードの実行結果は、以下のようになる。
$ io actor.io 1: obj1 1: obj2 2: obj1 2: obj2 3: obj1 3: obj2 Scheduler: nothing left to resume so we are exiting
別々に@@testメッセージを呼び出したobj1とobj2が、yieldで処理を譲り合うことで順番に出力を行っている事が分かる。
Ioにおいてはフューチャと呼ばれる機能も用意されていて、これは非同期呼び出しの「結果」を即座にオブジェクトとして利用出来る仕組みとなっている。メッセージ呼び出しに@をつけると結果を返す事が出来て、この時帰ってくるのがフューチャである。
1 futureResult := URL with("http://google.com/") @fetch 2 3 writeln("Do something immediately while fetch goes on in background...") 4 writeln("fetched ", futureResult size, " bytes") 5 writeln("end")
上記のコードの実行結果は、
$ io future.io Do something immediately while fetch goes on in background... fetched 9367 bytes end
となる。
ポイントは"Do something immediately while fetch goes on in background..."という出力が即座に行われる点で、これは1行目の@fetchの非同期呼び出しが別Threadで処理されて、現在のThreadでは即座に次の処理が行われる為である。4行目でfutureResultを使おうとしている為、その時点で@fetchの処理が終わってなかった時に初めて処理がブロックされる。特殊な事をしなくても、非同期に呼び出しておいてその結果を必要になったタイミングで使えるので使い勝手が良さそうである。
いったんまとめ
Ioだけで結構長くなったのでいったんまとめる。Ioでは、メッセージングとその非同期呼び出しというシンプルな構造で、コルーチン、アクター、フューチャといった便利な機能を実現している。並行処理についてはこれまであんまり意識した事が無かったけど、イメージをつかめた気がする。
どうでも良い話だけど、coroutineを知った事でgoのgoroutineという名前の意味もやっと分かった気がする。
goroutineはgo文で関数を実行する事で非同期に起動される手続きで、channelを使って値をやり取りできる。channelは値の受信時に処理をブロックする。その為、channelを使うことでgoroutine同士の同期をとる事が出来て、coroutineとしての機能を実現する事も出来る。そこから、coroutineっぽい名前(goroutine)がつけられたんだと思う。
ちょっと調べたら
"Users of C#, Lua, Python, and others might notice the resemblance between Go's generators/iterators and coroutines. Obviously, the name "goroutine" stems from this similarity"
っていう記述を見つけたから間違いなさそう。
Go Language Patterns: Coroutines
Prolog, Erlangについて
Prologは論理制約プログラミグが出来る言語で、制約の元で非決定性計算を行うっぽい。ErlangはPrologを出発点としてるからシンタックスは似てるけど、一番の強みはそこじゃなくて「平行性と耐障害性」らしい。Threadでもプロセスでも無い「軽量プロセス」という単位で大量の平行処理を行わせる事ができて、メッセージングによって協調的な動作をさせたり死活監視や再起動を簡単に行えたりする。これがものすごく良いらしくて、熱く語ってるブログも見つけた。
実は元々Erlangに一番興味があって「7つの言語 7つの世界」という本を借りたので、良い勉強になった気がする。
これらの言語については、また今度詳しくまとめるかもしれない。

- 作者: Bruce A. Tate,まつもとゆきひろ,田和勝
- 出版社/メーカー: オーム社
- 発売日: 2011/07/23
- メディア: 単行本(ソフトカバー)
- 購入: 9人 クリック: 230回
- この商品を含むブログ (61件) を見る
ノーマン先生の「誰のためのデザイン?」を読んだ。
ノーマン先生の「誰のためのデザイン?」を読んだ。
この本では、身の回りの物の「使いにくさ」が人の認知構造も踏まえながら考察されている。最後には、その成果が「デザインの7原則」としてまとめられている。豊富な例のおかげで読み易くかつ理解し易い作りになっているが、決して平易なだけでは無く学びの多い内容となっている。
古い本ではあるが、今でも色あせる事の無い良書だと思う。
デザインの7原則
- 外界にある知識 と頭の中にある知識の両者を利用する
- 作業の構造を 単純化 する
- 対象を目に見えるようにして、実行のへだたりと評価のへだたりに橋をかける( 可視性 )
- 対応づけ を正しくする
- 自然の制約や人工的な制約などの 制約 の力を活用する
- エラー に備えたデザインをする
- 以上のすべてがうまくいかないときには 標準化 をする
以上7つがデザインの7原則としてまとめられていた。それぞれの原則の意味については、以下のブログで分かり易く説明がなされている。
人間中心のデザインの原則 -『誰のためのデザイン?』を読んで-
1の外界にある知識の利用、3の可視性、4の対応付け、5の制約の利用については、若干意味の被りがある(と僕には思える)ものの、これらの原則は良いデザインを提供する為の優れた指針となっている。
原則の意味の被りについて
3の 可視性 はものすごく広い概念で、本書を通じて重要性を強調されているものでもある。何故ならば、システムの 目に見える 部分が「システムイメージ」であり、そこからユーザーは独自のメンタルモデル(ユーザーのもつモデルと呼ばれる)を作り上げるからである。使い易さの為には適切なメンタルモデルの構築が重要であり、その為には一貫した振る舞いや状態を示すシステムイメージが必要となる。
本書に記載されている原則としての可視性について言及しておくと、行為側での可視性は、「何が実行可能であり、どうやったら良いかが分かる事」と説明されている。これはまた、「意図とその時点でユーザが実行出来る行為」の自然な対応付けがつく事であるとも言える。この実現の為に、外界にある知識を利用したり制約を利用したりする事が出来る。対象の形状や特性が持つアフォーダンスも重要なヒントとなる。
評価側での可視性は「自分の行った行為がどんな効果を及ぼしたのかが分かる事」と説明されている。これはまた、「行為とその効果」の自然な対応付けがつく事であるとも言える。
以上を踏まえると、「目に見える制約やヒントによって可能かつ適切な行動が分かり、さらに適切な結果も目に見える事で良い対応関係を作れるようにする」といった文に1, 3, 4, 5の原則はまとめられるのでは無いだろうか。
そこに、単純化、エラーへの備え、標準化といった原則が追加されているのだと思う。
本書を読んでの所感
「誰のためのデザイン?」を読んだ時、「使いにくさ」や「不自然さ」の要因がきちんと言語化されていたのが僕にとっては衝撃的だった。これまで、何かを使ってみた時に「使いにくい」と判断する事はよくあったが、何故使いにくいのかまではきちんと言語化出来てなかった。
最初は使いにくいエディタ
パッと思いつく例としては、例えば「vim」や「emacs」の様なエディタがある。これらは使いこなせればものすごく生産性が上がるものの、最初はものすごく使いにくい作りとなっている。この使いにくさは、「外界にある知識」をほとんど利用出来ていない事に起因している。キーバインドを覚えて「頭の中の知識」として蓄えなければほとんど操作が行えず、可能な行動を絞り込む「制限」も無い(しいて言えば何かキーを入力すべきというくらいである)。これでは、最初は使いにくくて当然である。
そういった意味では、GUIアプリケーションにおいて「ボタン」や「タブ」(どちらもクリックする事をアフォードしている)といった部品が存在する事、「×ボタンをクリックする事でアプリケーションを終了する」といった標準化された振る舞いがある事は、「使い易さ」を高める大きな要因となっている。
では、エディタを使いこなした時の生産性の向上は何に由来するのだろうか? 本書においては、「頭の中に蓄えられた知識を利用した行動」の利点として、外界の知識を利用する場合に比べてはるかに高速に行う事が出来るという傾向の存在が指摘されている。これがエディタを使いこなした時の生産性の向上に繋がっているのでは無いかと考えられる。
他にも多くの例が考えられると思う。
今週の読書記録
達人プログラマーは今最終章(8章)なのでもうすぐ読み終わりそう。Land of Lispは手を動かす部分(ゲーム作る部分)をすっとばして一通り読んだ。ちなみに、これは半分以上すっとばした事になる。パターン認識と機会学習はチマチマ読んでてもうすぐ2章終わるとこ。t分布が出てきてめちゃめちゃ懐かしかった。
図書館の便利さを再認識した
最近お金が無くて本が買えなくてつらかったんだけど、大学の図書館に行けば無料で本が手に入る事に気づいた。特に、名著と呼ばれる類の本は大体置いてあったりして、めちゃめちゃすごい。
とりあえず気になってた本とかパッと目についた本を借りまくってみた。
「Team Geek」と「Googleを支える技術」は読み終わった。簡単に感想を書いてみる。
Team Geek
Team Geekはいろんなとこで感想を見かけるけど、確かに面白くて読み易いし印象に残る良い本だった。
有名なのはHumility(謙虚), Respect(尊敬), Trust(信頼)の3本柱で、通称「HRT(ハート)」と呼ばれる。良いソフトウェア開発を支えるのは良い人間関係という前提(それは筆者達が経験的に学んだ事でもある)の元、筆者らはHRTの精神の重要性を説いている。筆者ら曰く、
あらゆる人間関係の衝突は、謙虚・尊敬・信頼の欠如によるものだ。
らしい。
「個人としての活躍」よりも「チームとしての生産性」が重視されていて、例えどんなに個人レベルで優秀であろうと悪い文化を作る人(例えば人を平気で誹謗中傷するような人)はチームにいるべきでは無い。より正確には 悪い振る舞い がチームからは排除されるべきで、意図せず 悪い振る舞い をしてしまっている人にはそれを正す様にこちらから注意深く働きかけなければならない。
例えば、コードレビューにおいてやたらと攻撃的な批評をしてしまう人には、注意を呼びかける必要がある。建設的な批評は重要だが、相手の人格を否定したりしてはいけない(例:「こんなクソコードを書くなんて頭がおかしいんじゃ無いか!!」)。振る舞いが直らないなら、その人にはチームを去ってもらう事になる。
人の感情に配慮する事の重要性も指摘されていた。これに関しては、このブログの例(これもTeam Geekの感想)が分かり易い。どんなに論理的には正しい指摘であっても「あなたは間違ってる」って言われたら腹が立ってしまうので、言い回しなんかにも気をつけなければならない。これは僕の考えなんだけど、そもそも人の行動やパフォーマンスに対する「感情」の影響というのはかなり大きいので、それを無視してしまうのはナンセンスだと思う。この部分には納得出来たし、共感出来た。
リーダーとしての良い振る舞いにも言及されていた(というかそれが一番ページ数を占めてて)。リーダーはチームのメンバーを管理しようとしてはならず、メンバーを信頼して任せなければならない。求められるのは、サーバントリーダーシップである。
これに関しては、最近発売された「How Google Works」でも言及されてるっぽい。
http://engineer.typemag.jp/article/howgoogleworks
「Team Geek」、読み易くて納得出来る部分も多くて良い本だと思う。
Googleを支える技術
この本は、Googleの巨大分散システムについて筆者が論文とか読んで調べた内容をまとめたもの。発売日が2008年とけっこう古くて、扱ってる論文も2003年とか新しくても2006年とかでけっこう古いものなんだけど、それでも超巨大分散システムの確立された技術について説明されてて、やっぱGoogleすげえなって思った。
これまで分散システムとか使った事無くてこの辺の分野のセンスは全くなかったんだけど、Google File System, BigTable, Chubbyみたいな分散システムについて分かり易く説明されてて、簡単なイメージはつかめたと思う。
ちょっと前にnaoyaさんのブログでBigQueryとか分散システムについて触れられていたのを見てから、「Googleを支える技術」は最低限読んでおきたい本だとは思ってたので、この機会に目を通せて良かったと思う。
個人的には、しばらくはこれ程までに大規模な分散システムが必要になるシーンは無いと思うけど、こういった事が可能なんだって事は認識しておきたい。
読んでる途中のやつ
まだ読んでる途中のやつについてもちょろっと書いていく。どれも今週借りたやつ、かつ並行してるのであんま進んでない。
プロセッサを支える技術
CPUみたいなプロセッサがどんな仕事をしてるのかをまとめた本。図書館に行った時点では全く念頭に置いてなかったのに、パラ見したら面白そうだったので思わず借りた。
プロセッサが内部でどんな事をしてるか、プロセッサがメモリやI/O機器とどうコミュニケーションをとってるかが分かり易く説明されてた。何となく聞いた事はあるけどよく知らない単語が説明されてたりしてて(x86の語源とかARMとインテルのプロセッサの違いとか)、勉強になった気がする。
ちなみに、amazonのカスタマーレビューでちょいちょい記述が間違ってるって指摘されてて、気になったので軽くだけど調べてみた。
仮想記憶についてはWikipeditaのページがあるんだけど、確かに本文中の説明(実メモリよりもずっと大きいディスク容量分のメモリがあるように見せられる方式が「仮想記憶」)は誤解を生むかもしれない。
あと、32ビットプロセッサとか64ビットプロセッサとか言う場合、通常は「汎用レジスタ」のビット数が何ビットかで区別するっぽい。これもWikipediaのページに記述があった。
汎用レジスタは整数演算用データだけでなくメモリアドレスも保持する事になるので、使えるメモリ量が汎用レジスタのビット数によって制限される事になる。「64ビットなら4GB以上のメモリが効率良く使える」とかよく言われるのはその為である。
こういった突っ込みどころはあるっぽいけど、総じて良い本だと思う。まだ途中(3章半ばくらい)だけど、満足した。1, 2章がプロセッサの処理全体のざっくりした説明で、3章以降で細かい部分(高速化の為の仕組みとか)についてのより詳細な解説になってるんだけど、後は気になったとこだけつまみ食いする予定。
達人プログラマー
古典的名著として有名な本。気になってたので借りた。
けっこう初っ端で有名な「DRY原則」が出て来て嬉しかった。「DRYの為にコードを自動生成する」とかサラッと言ってて、さすが達人って感じだった。
あと、変更に対して柔軟であれと説いていたり、素早く作ってフィードバックを得て開発のサイクルを回す方法(これを閃光弾による開発と呼んでる)を薦めていたりして、何かアジャイルっぽいなーと思ったら筆者(Andy HuntとDave Thomasがどっちもアジャイルマニフェストの共著者だった。よく考えたら「達人プログラマー」を知ったのもアジャイルサムライの中で言及されてたからだった気がするので、無駄な気付きをしてしまった。
まだ3章まで呼んだとこで、これ以降も面白そうなので楽しみ。
パターン認識と機械学習
黄色い本。これも有名なヤツ。取っ付きにくい印象だったけど、パラ見してみたら思いのほか説明が丁寧で良さそうだったので借りた。
まだ1章を読んだとこだけど、全体を包括した良い導入だった。特に、確率をランダムな繰り返し試行の頻度とみなす「頻度主義的な見方」に対して、「不確かさの度合いとして確率を見る」という「ベイズ的な見方」が導入されていたのが印象的だった。ベイズ的な見方、最初は全くピンと来なかったんだけど、フィッティングの際のモデルパラメータの不確かさに着目するって話が分かり易かった(頻度的な見方だと、与えられたパラメータの元で「データ点が得られる確率」に着目する)。
読み進めるのに時間はかかりそうだけど、勉強にはなると思う。
Land of Lisp
Lisp alienの表紙が印象的な本。けっこう最近発売されてて、発売直後はブログとかでめちゃめちゃ取り上げられてた気がする。分厚いからビビってたけど、めちゃめちゃ読み易い。
実はCommon Lispは「ハッカーと画家」に触発された頃に一度勉強してて、竹内先生の「初めての人のためのLISP」もちょろっと読んでみたりはしてたんだけど、途中で飽きて放置しちゃってたので良い機会になった。
これもまだ5章(全部で20章ある)。読み易いので一気に読み進めたい。
まとめ
図書館めちゃめちゃすごい。かなり良い気付きだった。
どうでも良い話
これ一応技術ブログって事になってるんだけど、今回は単なる読書感想文になってしまった気がしてちょっと気がかり。
あと、ちょっと前に読んだ本だと「ビジョナリー・カンパニー2」と「誰の為のデザイン?」ってのがあって、どちらも印象に残る部分や自分の価値観に変化を与えてくれる部分があったので、いつか感想を書き残しておきたいと思う。

Team Geek ―Googleのギークたちはいかにしてチームを作るのか
- 作者: Brian W. Fitzpatrick,Ben Collins-Sussman,角征典
- 出版社/メーカー: オライリージャパン
- 発売日: 2013/07/20
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (19件) を見る
")
Googleを支える技術 ?巨大システムの内側の世界 (WEB+DB PRESSプラスシリーズ)
- 作者: 西田圭介
- 出版社/メーカー: 技術評論社
- 発売日: 2008/03/28
- メディア: 単行本(ソフトカバー)
- 購入: 47人 クリック: 1,166回
- この商品を含むブログ (374件) を見る
")
プロセッサを支える技術 ??果てしなくスピードを追求する世界 (WEB+DB PRESS plus)
- 作者: Hisa Ando
- 出版社/メーカー: 技術評論社
- 発売日: 2011/01/06
- メディア: 単行本(ソフトカバー)
- 購入: 22人 クリック: 250回
- この商品を含むブログ (50件) を見る

- 作者: アンドリューハント,デビッドトーマス,Andrew Hunt,David Thomas,村上雅章
- 出版社/メーカー: ピアソンエデュケーション
- 発売日: 2000/11
- メディア: 単行本
- 購入: 42人 クリック: 1,099回
- この商品を含むブログ (348件) を見る

- 作者: C.M.ビショップ,元田浩,栗田多喜夫,樋口知之,松本裕治,村田昇
- 出版社/メーカー: 丸善出版
- 発売日: 2012/04/05
- メディア: 単行本(ソフトカバー)
- 購入: 6人 クリック: 33回
- この商品を含むブログ (15件) を見る

- 作者: M.D. Conrad Barski,川合史朗
- 出版社/メーカー: オライリージャパン
- 発売日: 2013/02/23
- メディア: 大型本
- 購入: 1人 クリック: 18回
- この商品を含むブログ (19件) を見る
")
誰のためのデザイン?―認知科学者のデザイン原論 (新曜社認知科学選書)
- 作者: ドナルド・A.ノーマン,D.A.ノーマン,野島久雄
- 出版社/メーカー: 新曜社
- 発売日: 1990/02
- メディア: 単行本
- 購入: 37人 クリック: 945回
- この商品を含むブログ (288件) を見る

- 作者: ジム・コリンズ,山岡洋一
- 出版社/メーカー: 日経BP社
- 発売日: 2001/12/18
- メディア: 単行本
- 購入: 24人 クリック: 210回
- この商品を含むブログ (187件) を見る
代入を使わずに状態を表現する
最近、SICPのWeb版が存在する事に気づいて、空いた時間にちょろちょろと読んでいた。SICPって有名だし軽く目を通しておくかな、ってくらいの気持ちだったんだけど、3章、特に3.5章のストリームの話はめちゃくちゃ面白くて興味深かったので、ブログにもまとめて置く事にした。
ストリームというのは「状態の変遷を並びとして表現するデータ構造」で、特に3.5章では遅延評価されるリストとして実装されていた。代入を使わずに状態の変遷を表現する事が出来るという意味で、大変興味深い。
状態の変遷を並びとして表現するとは?
通常、状態の変遷というのは変数への再代入によって表現される。例えば、ある変数iの状態が1から10まで変化するといった場合、
for (int i = 1; i < 11; i++) { printf("%i\n", i); }
の様に、変数iに次々と新しい値を代入する事で状態の変化を表現する。
一方、並びとして状態を表現するというのは、1から10までの値の変化を[1 2 3 4 5 6 7 8 9 10]のような1から10までの値が順に並ぶリストで表現する事に相当する。つまり、「次の状態への変化」を「並びの次の要素を返す事」として表現出来るという事である。
上記のコードと同様の事をしたければ、リストの各要素に対してprintf関数を適用すれば良くて、例えばunderscore.jsのeachメソッドの様なものを考えれば、
_.each([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], function(i) { console.log(i); });
の様に各要素に対して順に関数を適用する形で表現出来る。
ここまでの例から、並びによって状態を表現する事には成功した。ただ、上記の例では最初から変遷する状態が(1から10までと)固定されていたから有限の長さのリストで表現出来たが、実際には次の状態がユーザーからの入力によって決まったり、プロセスが停止しない限りは永遠に変遷が続いたりする事もあり得る。そこで、 遅延評価 という概念が登場する事になる。
遅延評価 とは必要になるまで値の評価を送らせられるような評価方法の事で、 遅延評価 を用いればユーザーの入力が無いと表現出来ない要素を持つリストを作ったり、無限の長さを持つリストを作ったり出来る。
この 遅延評価 されるリストの事を、この場では特別なデータ構造として ストリーム と呼ぶ事にする。
ストリームの実装
SICPにおいてはscheme(LISPの方言の一つで、シンプルさがウリ)を用いて様々な概念の説明や実装がなされていたので、ここでもschemeを用いてストリームを実装したいと思う。
その前に、まずは通常のリストがschemeにおいてはどの様に表現されるかを説明する。
schemeにおけるリスト
scheme(というかLISP)においては、基本のデータ構造は値の ペア となっている。下図はSICPの図2.2から借用したもので、1と2のペアを表現している。
ペア はcons関数を2つの引数に適用する事で作る事が出来る。例えば、上記の1と2のペアは
(cons 1 2)
というコードを評価する事で作る事が出来る。ちなみに、schemeのコードは括弧で囲った第一要素が「関数」、それ以降に続く要素が「引数」として評価される。
この ペア を入れ子にする事で「リスト」と呼ばれるデータ構造を作る事が出来る。(ちなみに、schemeにおけるリストは、一般的なデータ構造の名称で呼ぶなら「連結リスト」である)
下図は、SICPの図2.4から借用した借用したもので、1から4までの整数からなるリストを表現している。
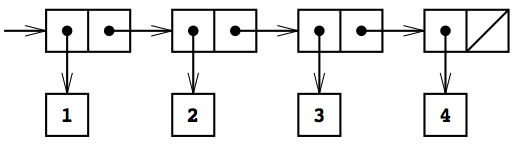
schemeのコードで表せば、
(cons 1 (cons 2 (cons 3 (cons 4 nil))))
を評価する事で上図のリストが返ってくる。また、任意の数の引数を受け取ってリストを生成出来るlist関数を使えば、
(list 1 2 3 4)
というコードでも良い。実行結果のリスト構造は、(1 2 3 4)という括弧でか囲まれた要素の並びとして表現される。
ペアやリストから要素を取り出すには、carやcdrという関数を使う。carはペアの第一要素を返す関数で、リストに適用しても第一要素が返る事になる。コードで書くと
(car (cons 1 2)) ;; 1が返る (car (list 3 4 5 6 7)) ;; 3が返る
の様な感じになる。cdrがペアの第二要素を返す関数で、リストに適用すると第二要素以降の要素からなるリストが返ってくる。
(cdr (cons 1 2)) ;; 2が返る (cdr (list 3 4 5 6 7)) ;; (4 5 6 7)が返る
これは、(list 3 4 5 6 7)が(cons 3 (list 4 5 6 7))と等価である事を考えればすんなり理解出来る。
carやcdrをくみ合わせれば、リストの任意の要素にアクセスする事が出来る。
(car (cdr (list 3 4 5 6 7))) ;; (4 5 6 7)というリストにcarを適用する事になるので、第二要素である4が返る
つまり、carやcdrがあれば、リストを操作する任意の処理を行う事が出来る。
ここまでで、リストを表現するにはcons, car, cdrが定義されれば良い事が分かった。
遅延評価されるリスト(ストリーム)を実装する
次に、遅延評価されるリストを実装する方法を考える。要は新しくそれ用のcons-stream, stream-car, stream-cdrを定義してやれば良い。
これらの内、特にのcons-streamの定義には、delayと呼ばれる関数(より正確には特殊形式)を使う。schemeにおいては、通常はコード内の各要素は評価がなされてから使われる(例えば(+ 1 (+ 1 2))のようなコードは先に内部の(+ 1 2)が3へと評価されてから(+ 1 3)の評価が行われる)んだけど、(delay <exp>)を評価する際には式<exp>は評価されず、 遅延オブジェクト と呼ばれるものが返ってくる。これは将来のある時点で<exp>を評価する「約束」と見なす事が出来て、 遅延オブジェクト に対してはforceという関数を適用した時に始めて内部の<exp>の評価が行われる。
大体のscheme処理系ではdelayやforceは組み込みで実装されている。例えばgaucheという処理系では
(delay (+ 1 2)) ;; #<promise 0x10068ee40> (force (delay (+ 1 2))) ;; 3
の様に#<promise 0x10068ee40>という形で遅延オブジェクトが表現され、forceを適用する事で内部の(+ 1 2)という式が評価される。
ぶっちゃけ上記の例だと何が嬉しいか分からないと思うけど、例えばdelayを使えばまだ存在しない変数を用いた計算式を遅延オブジェクトとして表現出来たりする。schemeではdefine関数を使って変数や関数の定義を行うんだけど、
(define x (delay (+ a b)))
の様に存在しない変数a, bを用いる遅延オブジェクトxを定義する事が出来る。変数aが未定義の状態でforceを適用すると、Errorが発生する。
(force x) ;; *** ERROR: unbound variable: a
一方、変数a, bを定義してからもう一度forceを適用すれば、ちゃんとした結果が得られる。
(define a 1) (define b 2) (force x) ;; 3が返る。
このように評価自体を送らせる事が出来るのが、遅延オブジェクトの大きな特徴である。
delayを実装する
delayは処理系で組み込みで実装されていると書いたけど、マクロとして自分で定義する事も出来る。
schemeにおけるマクロは、コードの置き換えを行う機能と考える事が出来る。例えば、(nil! x)を(setq x nil)に置換えられるべきマクロとして定義するには、
(define-syntax nil! (syntax-rules () ((_ x) (set! x '()))))
と書けば良い。(参考: https://www.shido.info/lisp/scheme_syntax.html)
define-syntaxがマクロ定義の為の関数で、第一引数としてマクロ名(上記の例ではnil!)、第二引数としてマクロの実体を受け取る。syntx-rulesがマクロを構成する為の関数で、第一引数は大抵空のリスト、第二引数に変換元と変換先の形式を記述したリストを渡す。_はマクロ名を表しているので、上記のコードは(nil! x)を(set! x '())へ変換するという意味になる。
実際、(nil! x)を実行すると確かにxにnilがsetされる。
(define x 1) ;; xには1がsetされている (nil! x) ;; xには()がsetされている
nil!と同様に、delayも(delay <exp>)を(lambda () <exp>)へと変換するマクロとして定義出来る。(lambdaは無名関数を作る関数)
(define-syntax delay (syntax-rules () ((_ exp) (lambda () exp))))
すなわち、delayがマクロとして定義された場合には、
(define x (delay (+ a b)))
というコードは
(define x (lambda () (+ a b)))
というコードへと置換えられる事になる。これは、xが引数を受け取らずに(+ a b)の実行結果を返す関数として定義される事を意味している。別の表現を用いれば、上記のコードは
(define (x) (+ a b))
と等価である。この時、遅延オブジェクトというのは単なる関数なので、forceはただの関数呼び出しとして実装出来る。
(define (force delayed-object) (delayed-object))
ここまでで、delayとforceの定義には成功した。
ちなみに、delayとforceとしてはquoteとevalを用いる形式でも上手く定義出来そう。
;; delayの定義 (define-syntax delay (syntax-rules () ((_ exp) (quote exp)))) ;; forceの定義 (define (force delayed-object) (eval delayed-object (interaction-environment)))
ちょろっと試した感じだと、問題無く動きそうだった。
遅延評価されるリスト
delayを用いてcons-streamを定義する。cons-streamは、
(cons-stream <a> <b>)
が
(cons <a> (delay <b>))
と置換えられるようなマクロとして実装すれば良い。つまり、
(define-syntax cons-stream (syntax-rules () ((_ a b) (cons a (delay b)))))
となる。consで作られたペアのうち2つ目の要素が 遅延オブジェクト になっているのがおおきな特徴で、評価はstream-cdr適用時に行われる。
;; stream-carの定義 (define (stream-car stream) (car stream)) ;; stream-cdrの定義 (define (stream-cdr stream) (force (cdr stream)))
こうして、cdr以降(第二引数以降)の評価が遅延されるリストを作れる様になった。
streamの表現力はめちゃめちゃ高くて、例えば無限に1が続くストリームであるonesは次のコードで定義出来る。
(define ones (cons-stream 1 ones))
このコードは「onesとは先頭が1でその後にones(つまり1が無限に続くリスト)が続くリスト」って事を表現してて、抽象度の高い表現をそのままコードに落とし込めている。また、無限リストを表現出来るのもそもそも遅延評価のお陰である。
整数の並びももちろん表現出来る。
;; 無限に続く整数の並びであるintegersを定義 (define integers (cons-stream 1 (add-streams ones integers))) ;; add-streamを定義 (define (add-streams s1 s2) (stream-map + s1 s2)) ;; stream-mapを定義 (define (stream-map proc . argstreams) (if (stream-null? (car argstreams)) the-empty-stream (cons-stream (apply proc (map stream-car argstreams)) (apply stream-map (cons proc (map stream-cdr argstreams)))))) ;; the-empty-streamを定義 (define the-empty-stream '()) ;; stream-null?を定義 (define (stream-null? stream) (null? stream))
上記のコードでは、二つのストリームを受け取ってそれらを要素毎に足し合わせた新しいstreamを返すadd-streamを定義してから、add-streamを用いて無限に続く整数の並びであるintegersを定義している。integersの定義の仕方も面白くて、「整数というのは1から始まっていて、その後に『『1から始まる整数の並び』の各要素に1ずつ足したもの』が続く」という抽象度の高い表現がなされている。
ones, integersともに自身の定義に自身が登場するという再帰的な構造になっているのも面白い。ストリームは数列とも見なせて、ストリーム同士の抽象度の高い関係性がコードでそのまま表現出来たりする。
引数としてストリームSをとり, その要素がS0, S0 + S1, S0 + S1 + S2, ... となるようなストリームを返す関数partial-sumsも、簡単に定義出来る。
(define (partial-sums s) (cons-stream (stream-car s) (add-streams (stream-cdr s) (partial-sums s))))
反復をストリームとして表現する
ストリームが実装できたので、最初に意図していた「ストリームでの状態の表現」を考える。
例えば何かしらの反復処理が必要になる状況を考える。SICPで例として挙げられていたのは「ニュートン法によって平方根を求める問題」で、ストリームを用いない場合には手続きの逐次的な実行(状態変数の逐次的な更新)で反復処理がなされる。
;; 平方根を求める関数sqrt-iter (define (sqrt-iter guess x) (if (good-enough? guess x) guess (sqrt-iter (improve guess x) x))) ;; guessの値の更新 (define (improve guess x) (average guess (/ x guess))) ;; 停止条件 (define (good-enough? guess x) (< (abs (- (square guess) x)) 0.001))
一方、ストリームを用いた場合には、値の変遷は並びとして表現される。
;; 更新されて行く値の並びであるstream (define (sqrt-stream x) (define guesses (cons-stream 1.0 (stream-map (lambda (guess) (improve guess x)) guesses))) guesses) ;; streamの各要素を出力 (display-stream (sqrt-stream 2)) ;; 1.0 ;; 1.5 ;; 1.4166666666666665 ;; 1.4142156862745097 ;; 1.4142135623746899 ;; 1.414213562373095 ;; ...
sqrt-streamを引数に適用した結果、例えば(sqrt-stream 2)が返すのはあくまでストリームという データ構造 であるというのがポイントで、ストリームを受け取ってストリームを返す関数等を使って様々な手続きを施す事が出来る。
ストリームを用いて微分方程式を解く
微分方程式を数値的に解く場合、通常は離散的なステップ毎に次の値の計算を繰り返す。この手続きを記述する事を考えたとき、ストリームを用いる場合にはかなり抽象度の高い表現が出来る。
例えば、「dy/dt = f(y)」を数値的に解く(yのtに対する関数形を求める)場合を考える。この問題は、次のsolve関数を用いて解く事が出来る。
;; dy/dt = f(y) を数値的に解く為の関数solveを定義。引数としては、t = 0におけるyの初期値y0, tのステップ幅dtを受け取る。返されるのは、dtで刻まれた各tにおけるyの値の並びであるストリーム。 (define (solve f y0 dt) (define y (integral (delay dy) y0 dt)) (define dy (stream-map f y)) y) ;; 非積分関数のストリーム、初期値、ステップ幅を与える事で積分された関数のストリームを返す関数ingtegraを定義。 (define (integral delayed-integrand initial-value dt) (define int (cons-stream initial-value (let ((integrand (force delayed-integrand))) (add-streams (scale-stream integrand dt) int)))))
注目して欲しいのはsolve関数の定義で、内部ではyとdyの定義を行っているだけ、しかもその定義も「yはdy/dtを積分したものでありdy/dtはfにyを適用したものである」というかなり抽象度の高い表現になっている事である。これでもきちんと計算は実行される。
この場合も、時とともに変化していく値としてでは無く時間を変数とした値の並びとしての表現がなされている。
Functional Reactive Programmingとの関連
SICPを読んでて最初に「ストリーム」という単語や「代入ではなく並びによって状態の変化を記述する」という表現を見た時に、最近流行りのFRPのストリームを思い出した。 で、気になったのでちょろっと調べたけどこのへんの関連について言及してるページとかはあんまり多く無かった。
このページで自分と同じ様な疑問を持った人がいたっぽくて、質問と返答が載ってた。
まずFRPのストリームは[(Time,[a])]みたいな型を持つみたいで、今回実装したストリームとはTimeの有無で違いがある。今回実装したストリームはストリーム内での順序の情報しかないから別のストリームとのmergeとかが出来ないけど、[(Time,[a])]型であればTimeの値によって明確にどちらが先かが定義出来るので、mergeが可能である。
後、FRPのストリームの実装には「遅延評価されるリスト」以外にも様々な実装方法があるらしく、例えばObserver Patternが使用されていたりするらしい。確かに、Bacon.jsのソースちょろっとだけ読んだ感じだと、ストリーム生成の際にはDOMオブジェクトとかに対してイベントリスナの登録とかしてるっぽかった。上手くラップして隠蔽して、外からは並びとして見えるストリームを作ってるっぽい。
別のページではSICPのstreamに触れた後により進んだ議論として FRP を紹介してたから、同じ方向性を目指してるってのはあながち間違いではないのかもしれない。そもそもSICPがかなり古くて初等的な内容を扱ってる本だから、わざわざ議論の種にならないのかもしれない。
まとめ
並びとして状態の変遷を表現する方法を確認し、その為のデータ構造としてストリームと呼ばれる遅延評価されるリスト構造を定義した。schemeにおいては、たった2つのマクロ(delayとstream-cons)を定義するだけでこれだけ豊かな表現が出来るのが驚きで、とても興味深かった。
個人的に興味を持ってる(&世間的にも注目を集めてるっぽい)FRPにも繋がりそうで、勉強になって良かった。ついでに、FRPももうちょっと調べたい。