図書館の便利さを再認識した
最近お金が無くて本が買えなくてつらかったんだけど、大学の図書館に行けば無料で本が手に入る事に気づいた。特に、名著と呼ばれる類の本は大体置いてあったりして、めちゃめちゃすごい。
とりあえず気になってた本とかパッと目についた本を借りまくってみた。
「Team Geek」と「Googleを支える技術」は読み終わった。簡単に感想を書いてみる。
Team Geek
Team Geekはいろんなとこで感想を見かけるけど、確かに面白くて読み易いし印象に残る良い本だった。
有名なのはHumility(謙虚), Respect(尊敬), Trust(信頼)の3本柱で、通称「HRT(ハート)」と呼ばれる。良いソフトウェア開発を支えるのは良い人間関係という前提(それは筆者達が経験的に学んだ事でもある)の元、筆者らはHRTの精神の重要性を説いている。筆者ら曰く、
あらゆる人間関係の衝突は、謙虚・尊敬・信頼の欠如によるものだ。
らしい。
「個人としての活躍」よりも「チームとしての生産性」が重視されていて、例えどんなに個人レベルで優秀であろうと悪い文化を作る人(例えば人を平気で誹謗中傷するような人)はチームにいるべきでは無い。より正確には 悪い振る舞い がチームからは排除されるべきで、意図せず 悪い振る舞い をしてしまっている人にはそれを正す様にこちらから注意深く働きかけなければならない。
例えば、コードレビューにおいてやたらと攻撃的な批評をしてしまう人には、注意を呼びかける必要がある。建設的な批評は重要だが、相手の人格を否定したりしてはいけない(例:「こんなクソコードを書くなんて頭がおかしいんじゃ無いか!!」)。振る舞いが直らないなら、その人にはチームを去ってもらう事になる。
人の感情に配慮する事の重要性も指摘されていた。これに関しては、このブログの例(これもTeam Geekの感想)が分かり易い。どんなに論理的には正しい指摘であっても「あなたは間違ってる」って言われたら腹が立ってしまうので、言い回しなんかにも気をつけなければならない。これは僕の考えなんだけど、そもそも人の行動やパフォーマンスに対する「感情」の影響というのはかなり大きいので、それを無視してしまうのはナンセンスだと思う。この部分には納得出来たし、共感出来た。
リーダーとしての良い振る舞いにも言及されていた(というかそれが一番ページ数を占めてて)。リーダーはチームのメンバーを管理しようとしてはならず、メンバーを信頼して任せなければならない。求められるのは、サーバントリーダーシップである。
これに関しては、最近発売された「How Google Works」でも言及されてるっぽい。
http://engineer.typemag.jp/article/howgoogleworks
「Team Geek」、読み易くて納得出来る部分も多くて良い本だと思う。
Googleを支える技術
この本は、Googleの巨大分散システムについて筆者が論文とか読んで調べた内容をまとめたもの。発売日が2008年とけっこう古くて、扱ってる論文も2003年とか新しくても2006年とかでけっこう古いものなんだけど、それでも超巨大分散システムの確立された技術について説明されてて、やっぱGoogleすげえなって思った。
これまで分散システムとか使った事無くてこの辺の分野のセンスは全くなかったんだけど、Google File System, BigTable, Chubbyみたいな分散システムについて分かり易く説明されてて、簡単なイメージはつかめたと思う。
ちょっと前にnaoyaさんのブログでBigQueryとか分散システムについて触れられていたのを見てから、「Googleを支える技術」は最低限読んでおきたい本だとは思ってたので、この機会に目を通せて良かったと思う。
個人的には、しばらくはこれ程までに大規模な分散システムが必要になるシーンは無いと思うけど、こういった事が可能なんだって事は認識しておきたい。
読んでる途中のやつ
まだ読んでる途中のやつについてもちょろっと書いていく。どれも今週借りたやつ、かつ並行してるのであんま進んでない。
プロセッサを支える技術
CPUみたいなプロセッサがどんな仕事をしてるのかをまとめた本。図書館に行った時点では全く念頭に置いてなかったのに、パラ見したら面白そうだったので思わず借りた。
プロセッサが内部でどんな事をしてるか、プロセッサがメモリやI/O機器とどうコミュニケーションをとってるかが分かり易く説明されてた。何となく聞いた事はあるけどよく知らない単語が説明されてたりしてて(x86の語源とかARMとインテルのプロセッサの違いとか)、勉強になった気がする。
ちなみに、amazonのカスタマーレビューでちょいちょい記述が間違ってるって指摘されてて、気になったので軽くだけど調べてみた。
仮想記憶についてはWikipeditaのページがあるんだけど、確かに本文中の説明(実メモリよりもずっと大きいディスク容量分のメモリがあるように見せられる方式が「仮想記憶」)は誤解を生むかもしれない。
あと、32ビットプロセッサとか64ビットプロセッサとか言う場合、通常は「汎用レジスタ」のビット数が何ビットかで区別するっぽい。これもWikipediaのページに記述があった。
汎用レジスタは整数演算用データだけでなくメモリアドレスも保持する事になるので、使えるメモリ量が汎用レジスタのビット数によって制限される事になる。「64ビットなら4GB以上のメモリが効率良く使える」とかよく言われるのはその為である。
こういった突っ込みどころはあるっぽいけど、総じて良い本だと思う。まだ途中(3章半ばくらい)だけど、満足した。1, 2章がプロセッサの処理全体のざっくりした説明で、3章以降で細かい部分(高速化の為の仕組みとか)についてのより詳細な解説になってるんだけど、後は気になったとこだけつまみ食いする予定。
達人プログラマー
古典的名著として有名な本。気になってたので借りた。
けっこう初っ端で有名な「DRY原則」が出て来て嬉しかった。「DRYの為にコードを自動生成する」とかサラッと言ってて、さすが達人って感じだった。
あと、変更に対して柔軟であれと説いていたり、素早く作ってフィードバックを得て開発のサイクルを回す方法(これを閃光弾による開発と呼んでる)を薦めていたりして、何かアジャイルっぽいなーと思ったら筆者(Andy HuntとDave Thomasがどっちもアジャイルマニフェストの共著者だった。よく考えたら「達人プログラマー」を知ったのもアジャイルサムライの中で言及されてたからだった気がするので、無駄な気付きをしてしまった。
まだ3章まで呼んだとこで、これ以降も面白そうなので楽しみ。
パターン認識と機械学習
黄色い本。これも有名なヤツ。取っ付きにくい印象だったけど、パラ見してみたら思いのほか説明が丁寧で良さそうだったので借りた。
まだ1章を読んだとこだけど、全体を包括した良い導入だった。特に、確率をランダムな繰り返し試行の頻度とみなす「頻度主義的な見方」に対して、「不確かさの度合いとして確率を見る」という「ベイズ的な見方」が導入されていたのが印象的だった。ベイズ的な見方、最初は全くピンと来なかったんだけど、フィッティングの際のモデルパラメータの不確かさに着目するって話が分かり易かった(頻度的な見方だと、与えられたパラメータの元で「データ点が得られる確率」に着目する)。
読み進めるのに時間はかかりそうだけど、勉強にはなると思う。
Land of Lisp
Lisp alienの表紙が印象的な本。けっこう最近発売されてて、発売直後はブログとかでめちゃめちゃ取り上げられてた気がする。分厚いからビビってたけど、めちゃめちゃ読み易い。
実はCommon Lispは「ハッカーと画家」に触発された頃に一度勉強してて、竹内先生の「初めての人のためのLISP」もちょろっと読んでみたりはしてたんだけど、途中で飽きて放置しちゃってたので良い機会になった。
これもまだ5章(全部で20章ある)。読み易いので一気に読み進めたい。
まとめ
図書館めちゃめちゃすごい。かなり良い気付きだった。
どうでも良い話
これ一応技術ブログって事になってるんだけど、今回は単なる読書感想文になってしまった気がしてちょっと気がかり。
あと、ちょっと前に読んだ本だと「ビジョナリー・カンパニー2」と「誰の為のデザイン?」ってのがあって、どちらも印象に残る部分や自分の価値観に変化を与えてくれる部分があったので、いつか感想を書き残しておきたいと思う。

Team Geek ―Googleのギークたちはいかにしてチームを作るのか
- 作者: Brian W. Fitzpatrick,Ben Collins-Sussman,角征典
- 出版社/メーカー: オライリージャパン
- 発売日: 2013/07/20
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (19件) を見る
")
Googleを支える技術 ?巨大システムの内側の世界 (WEB+DB PRESSプラスシリーズ)
- 作者: 西田圭介
- 出版社/メーカー: 技術評論社
- 発売日: 2008/03/28
- メディア: 単行本(ソフトカバー)
- 購入: 47人 クリック: 1,166回
- この商品を含むブログ (374件) を見る
")
プロセッサを支える技術 ??果てしなくスピードを追求する世界 (WEB+DB PRESS plus)
- 作者: Hisa Ando
- 出版社/メーカー: 技術評論社
- 発売日: 2011/01/06
- メディア: 単行本(ソフトカバー)
- 購入: 22人 クリック: 250回
- この商品を含むブログ (50件) を見る

- 作者: アンドリューハント,デビッドトーマス,Andrew Hunt,David Thomas,村上雅章
- 出版社/メーカー: ピアソンエデュケーション
- 発売日: 2000/11
- メディア: 単行本
- 購入: 42人 クリック: 1,099回
- この商品を含むブログ (348件) を見る

- 作者: C.M.ビショップ,元田浩,栗田多喜夫,樋口知之,松本裕治,村田昇
- 出版社/メーカー: 丸善出版
- 発売日: 2012/04/05
- メディア: 単行本(ソフトカバー)
- 購入: 6人 クリック: 33回
- この商品を含むブログ (15件) を見る

- 作者: M.D. Conrad Barski,川合史朗
- 出版社/メーカー: オライリージャパン
- 発売日: 2013/02/23
- メディア: 大型本
- 購入: 1人 クリック: 18回
- この商品を含むブログ (19件) を見る
")
誰のためのデザイン?―認知科学者のデザイン原論 (新曜社認知科学選書)
- 作者: ドナルド・A.ノーマン,D.A.ノーマン,野島久雄
- 出版社/メーカー: 新曜社
- 発売日: 1990/02
- メディア: 単行本
- 購入: 37人 クリック: 945回
- この商品を含むブログ (288件) を見る

- 作者: ジム・コリンズ,山岡洋一
- 出版社/メーカー: 日経BP社
- 発売日: 2001/12/18
- メディア: 単行本
- 購入: 24人 クリック: 210回
- この商品を含むブログ (187件) を見る
代入を使わずに状態を表現する
最近、SICPのWeb版が存在する事に気づいて、空いた時間にちょろちょろと読んでいた。SICPって有名だし軽く目を通しておくかな、ってくらいの気持ちだったんだけど、3章、特に3.5章のストリームの話はめちゃくちゃ面白くて興味深かったので、ブログにもまとめて置く事にした。
ストリームというのは「状態の変遷を並びとして表現するデータ構造」で、特に3.5章では遅延評価されるリストとして実装されていた。代入を使わずに状態の変遷を表現する事が出来るという意味で、大変興味深い。
状態の変遷を並びとして表現するとは?
通常、状態の変遷というのは変数への再代入によって表現される。例えば、ある変数iの状態が1から10まで変化するといった場合、
for (int i = 1; i < 11; i++) { printf("%i\n", i); }
の様に、変数iに次々と新しい値を代入する事で状態の変化を表現する。
一方、並びとして状態を表現するというのは、1から10までの値の変化を[1 2 3 4 5 6 7 8 9 10]のような1から10までの値が順に並ぶリストで表現する事に相当する。つまり、「次の状態への変化」を「並びの次の要素を返す事」として表現出来るという事である。
上記のコードと同様の事をしたければ、リストの各要素に対してprintf関数を適用すれば良くて、例えばunderscore.jsのeachメソッドの様なものを考えれば、
_.each([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], function(i) { console.log(i); });
の様に各要素に対して順に関数を適用する形で表現出来る。
ここまでの例から、並びによって状態を表現する事には成功した。ただ、上記の例では最初から変遷する状態が(1から10までと)固定されていたから有限の長さのリストで表現出来たが、実際には次の状態がユーザーからの入力によって決まったり、プロセスが停止しない限りは永遠に変遷が続いたりする事もあり得る。そこで、 遅延評価 という概念が登場する事になる。
遅延評価 とは必要になるまで値の評価を送らせられるような評価方法の事で、 遅延評価 を用いればユーザーの入力が無いと表現出来ない要素を持つリストを作ったり、無限の長さを持つリストを作ったり出来る。
この 遅延評価 されるリストの事を、この場では特別なデータ構造として ストリーム と呼ぶ事にする。
ストリームの実装
SICPにおいてはscheme(LISPの方言の一つで、シンプルさがウリ)を用いて様々な概念の説明や実装がなされていたので、ここでもschemeを用いてストリームを実装したいと思う。
その前に、まずは通常のリストがschemeにおいてはどの様に表現されるかを説明する。
schemeにおけるリスト
scheme(というかLISP)においては、基本のデータ構造は値の ペア となっている。下図はSICPの図2.2から借用したもので、1と2のペアを表現している。
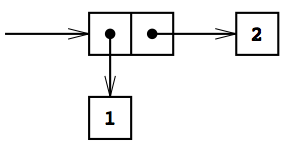
ペア はcons関数を2つの引数に適用する事で作る事が出来る。例えば、上記の1と2のペアは
(cons 1 2)
というコードを評価する事で作る事が出来る。ちなみに、schemeのコードは括弧で囲った第一要素が「関数」、それ以降に続く要素が「引数」として評価される。
この ペア を入れ子にする事で「リスト」と呼ばれるデータ構造を作る事が出来る。(ちなみに、schemeにおけるリストは、一般的なデータ構造の名称で呼ぶなら「連結リスト」である)
下図は、SICPの図2.4から借用した借用したもので、1から4までの整数からなるリストを表現している。
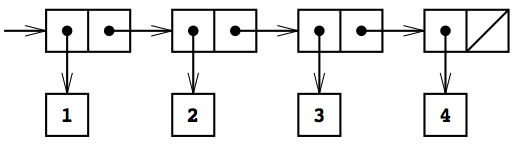
schemeのコードで表せば、
(cons 1 (cons 2 (cons 3 (cons 4 nil))))
を評価する事で上図のリストが返ってくる。また、任意の数の引数を受け取ってリストを生成出来るlist関数を使えば、
(list 1 2 3 4)
というコードでも良い。実行結果のリスト構造は、(1 2 3 4)という括弧でか囲まれた要素の並びとして表現される。
ペアやリストから要素を取り出すには、carやcdrという関数を使う。carはペアの第一要素を返す関数で、リストに適用しても第一要素が返る事になる。コードで書くと
(car (cons 1 2)) ;; 1が返る (car (list 3 4 5 6 7)) ;; 3が返る
の様な感じになる。cdrがペアの第二要素を返す関数で、リストに適用すると第二要素以降の要素からなるリストが返ってくる。
(cdr (cons 1 2)) ;; 2が返る (cdr (list 3 4 5 6 7)) ;; (4 5 6 7)が返る
これは、(list 3 4 5 6 7)が(cons 3 (list 4 5 6 7))と等価である事を考えればすんなり理解出来る。
carやcdrをくみ合わせれば、リストの任意の要素にアクセスする事が出来る。
(car (cdr (list 3 4 5 6 7))) ;; (4 5 6 7)というリストにcarを適用する事になるので、第二要素である4が返る
つまり、carやcdrがあれば、リストを操作する任意の処理を行う事が出来る。
ここまでで、リストを表現するにはcons, car, cdrが定義されれば良い事が分かった。
遅延評価されるリスト(ストリーム)を実装する
次に、遅延評価されるリストを実装する方法を考える。要は新しくそれ用のcons-stream, stream-car, stream-cdrを定義してやれば良い。
これらの内、特にのcons-streamの定義には、delayと呼ばれる関数(より正確には特殊形式)を使う。schemeにおいては、通常はコード内の各要素は評価がなされてから使われる(例えば(+ 1 (+ 1 2))のようなコードは先に内部の(+ 1 2)が3へと評価されてから(+ 1 3)の評価が行われる)んだけど、(delay <exp>)を評価する際には式<exp>は評価されず、 遅延オブジェクト と呼ばれるものが返ってくる。これは将来のある時点で<exp>を評価する「約束」と見なす事が出来て、 遅延オブジェクト に対してはforceという関数を適用した時に始めて内部の<exp>の評価が行われる。
大体のscheme処理系ではdelayやforceは組み込みで実装されている。例えばgaucheという処理系では
(delay (+ 1 2)) ;; #<promise 0x10068ee40> (force (delay (+ 1 2))) ;; 3
の様に#<promise 0x10068ee40>という形で遅延オブジェクトが表現され、forceを適用する事で内部の(+ 1 2)という式が評価される。
ぶっちゃけ上記の例だと何が嬉しいか分からないと思うけど、例えばdelayを使えばまだ存在しない変数を用いた計算式を遅延オブジェクトとして表現出来たりする。schemeではdefine関数を使って変数や関数の定義を行うんだけど、
(define x (delay (+ a b)))
の様に存在しない変数a, bを用いる遅延オブジェクトxを定義する事が出来る。変数aが未定義の状態でforceを適用すると、Errorが発生する。
(force x) ;; *** ERROR: unbound variable: a
一方、変数a, bを定義してからもう一度forceを適用すれば、ちゃんとした結果が得られる。
(define a 1) (define b 2) (force x) ;; 3が返る。
このように評価自体を送らせる事が出来るのが、遅延オブジェクトの大きな特徴である。
delayを実装する
delayは処理系で組み込みで実装されていると書いたけど、マクロとして自分で定義する事も出来る。
schemeにおけるマクロは、コードの置き換えを行う機能と考える事が出来る。例えば、(nil! x)を(setq x nil)に置換えられるべきマクロとして定義するには、
(define-syntax nil! (syntax-rules () ((_ x) (set! x '()))))
と書けば良い。(参考: https://www.shido.info/lisp/scheme_syntax.html)
define-syntaxがマクロ定義の為の関数で、第一引数としてマクロ名(上記の例ではnil!)、第二引数としてマクロの実体を受け取る。syntx-rulesがマクロを構成する為の関数で、第一引数は大抵空のリスト、第二引数に変換元と変換先の形式を記述したリストを渡す。_はマクロ名を表しているので、上記のコードは(nil! x)を(set! x '())へ変換するという意味になる。
実際、(nil! x)を実行すると確かにxにnilがsetされる。
(define x 1) ;; xには1がsetされている (nil! x) ;; xには()がsetされている
nil!と同様に、delayも(delay <exp>)を(lambda () <exp>)へと変換するマクロとして定義出来る。(lambdaは無名関数を作る関数)
(define-syntax delay (syntax-rules () ((_ exp) (lambda () exp))))
すなわち、delayがマクロとして定義された場合には、
(define x (delay (+ a b)))
というコードは
(define x (lambda () (+ a b)))
というコードへと置換えられる事になる。これは、xが引数を受け取らずに(+ a b)の実行結果を返す関数として定義される事を意味している。別の表現を用いれば、上記のコードは
(define (x) (+ a b))
と等価である。この時、遅延オブジェクトというのは単なる関数なので、forceはただの関数呼び出しとして実装出来る。
(define (force delayed-object) (delayed-object))
ここまでで、delayとforceの定義には成功した。
ちなみに、delayとforceとしてはquoteとevalを用いる形式でも上手く定義出来そう。
;; delayの定義 (define-syntax delay (syntax-rules () ((_ exp) (quote exp)))) ;; forceの定義 (define (force delayed-object) (eval delayed-object (interaction-environment)))
ちょろっと試した感じだと、問題無く動きそうだった。
遅延評価されるリスト
delayを用いてcons-streamを定義する。cons-streamは、
(cons-stream <a> <b>)
が
(cons <a> (delay <b>))
と置換えられるようなマクロとして実装すれば良い。つまり、
(define-syntax cons-stream (syntax-rules () ((_ a b) (cons a (delay b)))))
となる。consで作られたペアのうち2つ目の要素が 遅延オブジェクト になっているのがおおきな特徴で、評価はstream-cdr適用時に行われる。
;; stream-carの定義 (define (stream-car stream) (car stream)) ;; stream-cdrの定義 (define (stream-cdr stream) (force (cdr stream)))
こうして、cdr以降(第二引数以降)の評価が遅延されるリストを作れる様になった。
streamの表現力はめちゃめちゃ高くて、例えば無限に1が続くストリームであるonesは次のコードで定義出来る。
(define ones (cons-stream 1 ones))
このコードは「onesとは先頭が1でその後にones(つまり1が無限に続くリスト)が続くリスト」って事を表現してて、抽象度の高い表現をそのままコードに落とし込めている。また、無限リストを表現出来るのもそもそも遅延評価のお陰である。
整数の並びももちろん表現出来る。
;; 無限に続く整数の並びであるintegersを定義 (define integers (cons-stream 1 (add-streams ones integers))) ;; add-streamを定義 (define (add-streams s1 s2) (stream-map + s1 s2)) ;; stream-mapを定義 (define (stream-map proc . argstreams) (if (stream-null? (car argstreams)) the-empty-stream (cons-stream (apply proc (map stream-car argstreams)) (apply stream-map (cons proc (map stream-cdr argstreams)))))) ;; the-empty-streamを定義 (define the-empty-stream '()) ;; stream-null?を定義 (define (stream-null? stream) (null? stream))
上記のコードでは、二つのストリームを受け取ってそれらを要素毎に足し合わせた新しいstreamを返すadd-streamを定義してから、add-streamを用いて無限に続く整数の並びであるintegersを定義している。integersの定義の仕方も面白くて、「整数というのは1から始まっていて、その後に『『1から始まる整数の並び』の各要素に1ずつ足したもの』が続く」という抽象度の高い表現がなされている。
ones, integersともに自身の定義に自身が登場するという再帰的な構造になっているのも面白い。ストリームは数列とも見なせて、ストリーム同士の抽象度の高い関係性がコードでそのまま表現出来たりする。
引数としてストリームSをとり, その要素がS0, S0 + S1, S0 + S1 + S2, ... となるようなストリームを返す関数partial-sumsも、簡単に定義出来る。
(define (partial-sums s) (cons-stream (stream-car s) (add-streams (stream-cdr s) (partial-sums s))))
反復をストリームとして表現する
ストリームが実装できたので、最初に意図していた「ストリームでの状態の表現」を考える。
例えば何かしらの反復処理が必要になる状況を考える。SICPで例として挙げられていたのは「ニュートン法によって平方根を求める問題」で、ストリームを用いない場合には手続きの逐次的な実行(状態変数の逐次的な更新)で反復処理がなされる。
;; 平方根を求める関数sqrt-iter (define (sqrt-iter guess x) (if (good-enough? guess x) guess (sqrt-iter (improve guess x) x))) ;; guessの値の更新 (define (improve guess x) (average guess (/ x guess))) ;; 停止条件 (define (good-enough? guess x) (< (abs (- (square guess) x)) 0.001))
一方、ストリームを用いた場合には、値の変遷は並びとして表現される。
;; 更新されて行く値の並びであるstream (define (sqrt-stream x) (define guesses (cons-stream 1.0 (stream-map (lambda (guess) (improve guess x)) guesses))) guesses) ;; streamの各要素を出力 (display-stream (sqrt-stream 2)) ;; 1.0 ;; 1.5 ;; 1.4166666666666665 ;; 1.4142156862745097 ;; 1.4142135623746899 ;; 1.414213562373095 ;; ...
sqrt-streamを引数に適用した結果、例えば(sqrt-stream 2)が返すのはあくまでストリームという データ構造 であるというのがポイントで、ストリームを受け取ってストリームを返す関数等を使って様々な手続きを施す事が出来る。
ストリームを用いて微分方程式を解く
微分方程式を数値的に解く場合、通常は離散的なステップ毎に次の値の計算を繰り返す。この手続きを記述する事を考えたとき、ストリームを用いる場合にはかなり抽象度の高い表現が出来る。
例えば、「dy/dt = f(y)」を数値的に解く(yのtに対する関数形を求める)場合を考える。この問題は、次のsolve関数を用いて解く事が出来る。
;; dy/dt = f(y) を数値的に解く為の関数solveを定義。引数としては、t = 0におけるyの初期値y0, tのステップ幅dtを受け取る。返されるのは、dtで刻まれた各tにおけるyの値の並びであるストリーム。 (define (solve f y0 dt) (define y (integral (delay dy) y0 dt)) (define dy (stream-map f y)) y) ;; 非積分関数のストリーム、初期値、ステップ幅を与える事で積分された関数のストリームを返す関数ingtegraを定義。 (define (integral delayed-integrand initial-value dt) (define int (cons-stream initial-value (let ((integrand (force delayed-integrand))) (add-streams (scale-stream integrand dt) int)))))
注目して欲しいのはsolve関数の定義で、内部ではyとdyの定義を行っているだけ、しかもその定義も「yはdy/dtを積分したものでありdy/dtはfにyを適用したものである」というかなり抽象度の高い表現になっている事である。これでもきちんと計算は実行される。
この場合も、時とともに変化していく値としてでは無く時間を変数とした値の並びとしての表現がなされている。
Functional Reactive Programmingとの関連
SICPを読んでて最初に「ストリーム」という単語や「代入ではなく並びによって状態の変化を記述する」という表現を見た時に、最近流行りのFRPのストリームを思い出した。 で、気になったのでちょろっと調べたけどこのへんの関連について言及してるページとかはあんまり多く無かった。
このページで自分と同じ様な疑問を持った人がいたっぽくて、質問と返答が載ってた。
まずFRPのストリームは[(Time,[a])]みたいな型を持つみたいで、今回実装したストリームとはTimeの有無で違いがある。今回実装したストリームはストリーム内での順序の情報しかないから別のストリームとのmergeとかが出来ないけど、[(Time,[a])]型であればTimeの値によって明確にどちらが先かが定義出来るので、mergeが可能である。
後、FRPのストリームの実装には「遅延評価されるリスト」以外にも様々な実装方法があるらしく、例えばObserver Patternが使用されていたりするらしい。確かに、Bacon.jsのソースちょろっとだけ読んだ感じだと、ストリーム生成の際にはDOMオブジェクトとかに対してイベントリスナの登録とかしてるっぽかった。上手くラップして隠蔽して、外からは並びとして見えるストリームを作ってるっぽい。
別のページではSICPのstreamに触れた後により進んだ議論として FRP を紹介してたから、同じ方向性を目指してるってのはあながち間違いではないのかもしれない。そもそもSICPがかなり古くて初等的な内容を扱ってる本だから、わざわざ議論の種にならないのかもしれない。
まとめ
並びとして状態の変遷を表現する方法を確認し、その為のデータ構造としてストリームと呼ばれる遅延評価されるリスト構造を定義した。schemeにおいては、たった2つのマクロ(delayとstream-cons)を定義するだけでこれだけ豊かな表現が出来るのが驚きで、とても興味深かった。
個人的に興味を持ってる(&世間的にも注目を集めてるっぽい)FRPにも繋がりそうで、勉強になって良かった。ついでに、FRPももうちょっと調べたい。
遺伝的プログラミングの続き
2週間前に書いてた遺伝的プログラミングの続き。前は、構文木を構成するクラスとしてParamLeaf, ConstLeaf, EvalNodeを定義した。
書いたコード
前のコードにもdisplayメソッドとか付け加えた。後、rubyのオブジェクトはデフォルトではdeepcopyが出来ないので、childrenを持つEvalNodeにはinitialize_copyメソッドを持たせてdeepcopy時にchildのcopyを持たせる処理を書いた。
とりあえず、これがTreeのNode。
1 module GeneticProgramming 2 class Node 3 def display(indent = 0) 4 print "\s" * indent 5 end 6 end 7 8 class ParamLeaf < Node 9 def initialize(index) 10 @index = index 11 end 12 13 def eval(*params) 14 params[@index] 15 end 16 17 def display(indent = 0) 18 super(indent) 19 print "param#{@index}\n" 20 end 21 end 22 23 class ConstLeaf < Node 24 def initialize(const) 25 @const = const 26 end 27 28 def eval(*params) 29 @const 30 end 31 32 def display(indent = 0) 33 super(indent) 34 print "#{@const}\n" 35 end 36 end 37 38 class EvalNode < Node 39 def initialize(func_wrapper, *children) 40 @func_wrapper = func_wrapper 41 @children = children 42 end 43 44 def initialize_copy(obj) 45 @children = obj.children.map { |child| child.dup } 46 end 47 48 attr_accessor :children 49 50 def eval(*params) 51 results = @children.map { |e| e.eval(*params) } 52 @func_wrapper.call(*results) 53 end 54 55 def display(indent = 0) 56 super(indent) 57 print "#{name}\n" 58 @children.each { |child| child.display(indent + 1) } 59 end 60 61 def name 62 @func_wrapper.class.method_defined?(:name) ? @func_wrapper.name : 'no name' 63 end 64 end 65 end
EvalNodeにはprocオブジェクトを渡せるけど、display時に名前とか表示する為にFuncWrapperクラスを作った。後、FuncWrapperオブジェクトとして実際に使用するものを事前にまとめてFuncList moduleにした。
1 module GeneticProgramming 2 module FuncList 3 class FuncWrapper 4 def initialize(func_proc, name, arity = nil) 5 @proc = func_proc 6 @name = name 7 @arity = arity || func_proc.arity 8 end 9 10 attr_reader :name, :arity 11 12 def call(*args) 13 @proc.call(*args) 14 end 15 end 16 17 All = { 18 add: FuncWrapper.new(:+.to_proc, 'add', 2), 19 sub: FuncWrapper.new(:-.to_proc, 'sub', 2), 20 mul: FuncWrapper.new(:*.to_proc, 'mul', 2), 21 if: FuncWrapper.new(lambda { |pred, cons, alter| (pred > 0) ? cons : alter }, 'if', 3), 22 greater: FuncWrapper.new(lambda { |left, right| (left > right) ? 1 : 0 }, '>', 2) 23 } 24 25 def self.[](method_name) 26 All[method_name] 27 end 28 end 29 end
arityメソッドは引数の数を返すメソッドで、+とか*みたいな任意の数をとれるやつは任意の数をとれる形にしようかとも思ったけど、面倒だったのでとりあえず二引数扱いにしてる。FuncList::Allにこちらで事前に生成したFuncWrapperオブジェクトが入れてある。
それから、遺伝的プログラミングで問題を解くSolverクラスを作った。
1 require_relative './func_list' 2 require_relative './node' 3 4 module GeneticProgramming 5 class Solver 6 def initialize(score_obj, max_gen = 500, mutate_rate = 0.1, crossover_rate = 0.1, p_exp = 0.7, p_new = 0.5) 7 @score_obj = score_obj 8 @max_gen = max_gen 9 @mutate_rate = mutate_rate 10 @crossover_rate = crossover_rate 11 @p_exp = p_exp 12 @p_new = p_new 13 end 14 15 def select_index 16 Math.log(Math.log(rand) / Math.log(@p_exp)).to_i 17 end 18 19 def evolve(param_size, pop_size) 20 population = Array.new(pop_size) { |i| make_random_tree(param_size) } 21 scores = [] 22 @max_gen.times do |count| 23 scores = rank_func(population) 24 p scores[0][0] 25 break if scores[0][0] == 0 26 27 population[0] = scores[0][1] 28 population[1] = scores[1][1] 29 (2..pop_size).each do |i| 30 if rand > @p_new 31 tree1 = scores[select_index][1] 32 tree2 = scores[select_index][1] 33 population[i] = mutate(crossover(tree1, tree2, @crossover_rate), param_size, @mutate_rate) 34 else 35 population[i] = make_random_tree(param_size) 36 end 37 end 38 end 39 scores[0][1].display 40 scores[0][1] 41 end 42 43 def rank_func(population) 44 population.map { |tree| [@score_obj.get_score(tree), tree] }.sort_by { |score, tree| score } 45 end 46 47 def make_random_tree(param_size, max_depth = 4, f_prob = 0.5, p_prob = 0.6) 48 if rand < f_prob && max_depth > 0 49 func = FuncList::All.values.sample 50 childs = Array.new(func.arity) { |i| make_random_tree(param_size, max_depth - 1, f_prob, p_prob) } 51 EvalNode.new(func, *childs) 52 elsif rand < p_prob 53 ParamLeaf.new(rand(param_size)) 54 else 55 ConstLeaf.new(rand(10)) 56 end 57 end 58 59 def mutate(tree, param_size, change_prob = 0.1) 60 if rand < change_prob 61 make_random_tree(param_size) 62 else 63 result = tree.dup 64 if tree.class.method_defined?(:children) 65 result.children = tree.children.map { |child| mutate(child, param_size, change_prob) } 66 end 67 result 68 end 69 end 70 71 def crossover(tree1, tree2, swap_prob = 0.7, top = true) 72 if rand < swap_prob && !top 73 tree2.dup 74 else 75 result = tree1.dup 76 if tree1.class.method_defined?(:children) && tree2.class.method_defined?(:children) 77 result.children = tree1.children.map { |child| crossover(child, tree2.children.sample, swap_prob, false) } 78 end 79 result 80 end 81 end 82 end 83 end
これは、
solver = GenericProgramming::Solver.new(score_obj) solver.evolve(2, 500)
みたいな感じで使う。treeを引数としてとるget_obj(tree)メソッドを持つscore_objを渡してinitializeすると、そのscoreを遺伝的プログラミングで改善していって、最終的にscrore:0を返す様なtreeを表示してくれる。
score_objとしては、今回はこちらで用意した関数に対してrandomeに引数与えてデータセットを作って、そのデータセットとのズレの総和をscoreとして返す様なものを作った。
1 require_relative './solve' 2 3 class TestSet 4 def initialize(hidden_proc) 5 @hidden_proc = hidden_proc 6 @test_set = build_test_set 7 end 8 9 def build_test_set 10 [*0..200].map do |i| 11 x = rand(40) 12 y = rand(40) 13 [x, y, @hidden_proc.call(x, y)] 14 end 15 end 16 17 def get_score(tree) 18 @test_set.map { |x, y, test_value| 19 (tree.eval(x, y) - test_value).abs 20 }.reduce(:+) 21 end 22 end 23 24 if __FILE__ == $0 25 test_set = TestSet.new(lambda { |x, y| x ** 2 + 3 * y }) 26 GeneticProgramming::Solver.new(test_set).evolve(2, 500) 27 end
26行目にあるように、こちらで与えた関数でtest_setオブジェクトを作ってる。get_scoreメソッドにtreeを渡してやると、そのtreeがどれだけ良いものになってるかがscoreとして返る。
実際の実行結果はこんな感じになった。最初の数字の並びはscoreの変化で、その後にtree.displayの結果を表示してる。
$ ruby test_set.rb 11018 5594 0 add mul sub if param0 param0 > param0 0 0 param0 add mul param1 if > param1 param1 > param0 param0 2 param1
複雑に見えるけど> param1 param1(必ず0が返る)みたいなバカみたいな事をやってるだけで、ちゃんとx ** 2 + 3 * yにはなってる。こういった自明な部分を 枝刈り してやると、もっと綺麗な解になるらしい。
所感
大体は集合知プログラミングにのってたコードをrubyに置き換えただけだったけど、ちゃんと動いて問題を解くのに使えて楽しかった。
ちょこちょこ心残りはあって、solverは書いてて途中で力つきちゃってevolveが雑な実装になってしまった(ほぼ写経になってしまった)から、後でもうちょいリファクタリングしときたい。「遺伝的プログラミング」に載ってた定義だと引数が多すぎてイラッとしたからinitializeとevolveに分けたけど、特にinitializeの必要は無かったかもしれない。
後、mutate(突然変異)やcrossover(交叉)はTreeのクラスにメソッドとして持たしても良かったかもしれないし、make_random_treeはSolverクラスに入れたけどGeneticProgrammingモジュールの直下にあっても良い気がした。
眠くて辛いので今日はここまで。
追記
所感で書いた点を書き直してgithubにあげた。
south37/genetic_programming · GitHub
param_sizeメソッドとscoreメソッドが定義されたオブジェクトを渡してGeneticProgramming::Solverをinitializeすると、そのscoreを最小化するようなプログラム(構文木)の発見を目指して遺伝的アルゴリズムで探索してくれる。
require './solve.rb' GeneticProgramming::Solver.new(score_obj).evolve(500) # 遺伝的アルゴリズム開始
何らかの学習用のデータセットがあるとして、それをラップする形でscore_objオブジェクトを定義してやれば一応は動くはず。引数の数は任意だけど、score_objはparam_sizeメソッドで引数の数を返さなければならない。
ちゃんと正しい結果を返してくれるのかのテスト用に、こちらで正解の関数を与える事でデータセットを、さらにはそれを元にscore_objを作ってくれるTestSetクラスも用意されてる。
今日は遺伝的プログラミングの話ではなく、ポエムを書く
実はこのブログは焼き肉ブログという名前の「はてなブロググループ」に属してて、毎日順番にブログを書いてく取り決めをしていたりする。で、今グループを作ってからちょうど1年が経ったみたいで、振り返りをしようという流れがやってきている。
乗るしかない このビッグウェーブに!
って事で、振り返る。
4月にも振り返りっぽい事してた
ってことで、4月から今日までの6ヶ月について考えてみる。
といってもあんま大したことしてなくて、変わらず本読んでそれについてブログ書いてた。
ただ、最近はただ情報をまとめるだけじゃ良く無いなと思って、自分の体験や考えた事なんかを積極的に残す様にしてた。Web上にあんま落ちてない情報をまとめるならそこそこ価値はあるけど、多くの人が既にブログに書いてる様な事をほとんどコピペみたいな事しても情報としてそんなに価値は無くて、じゃあどうしたらいいかって言うとやっぱり自分の意見とか体験とかを残した方が良いのかなと思った。
エンジニアのブログとか読んでて一番価値を感じるのは「試行錯誤して問題解決した結果を分かり易くまとめてくれてる事」だったりするんだけど、業務とかしてなくてあんまり問題解決の知見を貯めたりは出来ないので、せめてインプットの際に考えた事なんかを残したい。
ちょっと困ってる事
ブログ書くとけっこう時間とられて一度にあんまり量書けないんだけど、技術書を読む事は隙間時間さえあれば四六時中やれちゃうので、結果としてアウトプットがインプットに追いついてない形になってる。まあ、学んだ事全てを書き残す必要は無いのかもしれないけど、このへんもうちょい上手くやれると良い。
あと、最近は昔から名著って呼ばれてるような本をちゃんと読みたいなと思ってるんだけど、「オブジェクト指向入門」とか「リファクタリング」とか大抵むっちゃ高いので、買えない。早くお金を稼ぎたい。
やりたい事
もっとポエムを書きたい。
自分はけっこうエンジニアブログとか読むの好きで、オブジェクト指向がどうとか関数型がどうとか盛り上がってるのを見ていろいろ自分で考えたりして楽しんでるんだけど、そこで考えた事とかを書き残しても良いんだと思う。
特に、僕はグレアムのポエム(エッセイとも言う)にかなり影響を受けている口なので、そういったWebポエムの影響力は理解してるつもりだし、そういった影響力のある存在には憧れる。
あとエンジニアリング以外のトピックについてもいろいろ考えてて、「リーダーの資質とは」とか「努力について」とか「環境が行動を左右する」とかそのへんについては、いつか考えてる事を書きたい。
時代はポエムなのかもしれない。
学びたい事
自分が乗っかってるものの事をもっとちゃんと理解したい。特に最近は、Unixとか計算機の低レイヤーの仕組みとか由緒正しきオブジェクト指向の考え方とかについてちゃんと学ぼうと思ってる。ちょろちょろとは勉強してるけど、まだまだ全然詳しくはなれてない。理解を深めて行きたい。
心がけてる事
自戒をこめてなんだけど、自分が今手にしてるものを過大評価し過ぎちゃダメだと思ってる。例えば、自分は言語としてはRubyが好きでWAFとしてはRuby on Railsが大好きなんだけど、これらが最もクールで他は全部クソみたいな事は絶対言っちゃいけないと思ってる。
特に、新しい言語やライブラリ、フレームワーク、ツールなんかが生まれ続けてる現状の中で、自分が今知っている知識を不当に評価するあまり新しいものを頭ごなしに否定するようではいけないと思う。人は心理的に自分の行動を正当化するバイアスが働くらしく、特定の技術にお金や時間を費やす程それを高く評価してしまう。これは「酸っぱいブドウ」とかと同じ話で、「認知的不協和」として知られている。
こういった事は頭に入れておいて、理性でバイアスを抑えつける様にしたい。
ちなみに、「認知的不協和」とかの話は「Hooked ハマるしかけ」に載ってた。けっこう面白かったので、良い本だと思う。
まとめ
振り返りは一瞬で終えて、ほぼポエムを書いてしまった。やはり時代はポエムなのかもしれない。
遺伝的プログラミングを学ぶ
積読されてた「集合知プログラミング」を引っ張りだして読んだ。面白そうなとこから読んでたからまだちょこちょこ抜けはあるけど、機械学習のいろんな手法を分かり易く説明してくれてて楽しく読めた。 その中でも、遺伝的プログラミングの考え方が特に面白く感じた。
遺伝的プログラミングとは?
機械学習によって「プログラム」を構築する手法。ランダムに作られたプログラムの中から、良いものを選んで「突然変異」させたり「交配」させたりしながら進化させていく。
最適化手法の一つである「遺伝アルゴリズム」を「プログラム」自体に適用したものとも言えて、「プログラム」を生成するプログラムを考えようっていうメタな感じが面白い。
実際どうやんの?
ランダムに「プログラム」を作ろうって時、原理的には適当に作った文字列をevalするとかでも良いんだろうけど、そういった方法ではちゃんと動くコードになる確率は限りなく小さい。そこで、通常は「構文木」に着目する。
「構文木」というのは再帰的に評価可能なツリー構造の事で、例えば通常のプログラミング言語においてはコンパイルの際にコードはいったん構文解析によって「構文木」(より正確には抽象構文木)に変換され、その後で実行可能なバイナリの生成が行われる。
このページの図11みたいなイメージを持ってもらえればOK。
この構文木を「遺伝アルゴリズム」で進化させていこうというのが、遺伝的プログラミング。
構文木を作ってみる
より正しくは構文木と一対一で対応する様なツリー構造を、オブジェクトとして表現してみる。
まず、ツリーを構成するノード(および末端のリーフ)として、パラメータに対応するParamLeaf、定数に対応するConstLeaf、そして子ノードに対して適用されて値を返すEvalNodeの3種類を考える。特に、EvalNodeは関数の場合もあればifのような制御構造の場合もある事に注意する。
例えば、rubyでは次の様にParamLeafクラス, ConstLeafクラス, EvalNodeクラスを定義出来る。
1 class ParamLeaf 2 def initialize(index) 3 @index = index 4 end 5 6 def eval(*params) 7 params[@index] 8 end 9 end 10 11 class ConstLeaf 12 def initialize(const) 13 @const = const 14 end 15 16 def eval(*params) 17 @const 18 end 19 end 20 21 class EvalNode 22 def initialize(eval_ploc, *children) 23 @eval_ploc = eval_ploc 24 @children = children 25 end 26 27 def eval(*params) 28 results = @children.map { |e| e.eval(*params) } 29 @eval_ploc.call(*results) 30 end 31 end
これで、例えば次の様にツリー構造を作って、それをevalする事が出来るようになった。
[1] pry(main)> tree = EvalNode.new(lambda { |a, b| a + b }, ConstLeaf.new(1), ConstLeaf.new(2)) => #<EvalNode:0x007fe7f04a4360 @children=[#<ConstLeaf:0x007fe7f04a43b0 @const=1>, #<ConstLeaf:0x007fe7f04a4388 @const=2>], @eval_ploc=#<Proc:0x007fe7f04a43d8@(pry):17 (lambda)>> [2] pry(main)> tree.eval => 3
上記の例では、「1 + 2」というコードに対応する構文木を作った事になる。一部をパーツとして取り替え可能な「データ構造」の形でプログラムを表現した事で、遺伝的アルゴリズムが適用出来る様になった。
ちなみにどうでも良い話だけど、単純な演算ならlambda式では無くsymbolのto_procメソッド使うとちょっとオシャレになる。
tree = EvalNode.new(:+.to_proc, ConstLeaf.new(1), ConstLeaf.new(2))
時間が無くなった
めちゃくちゃ中途半端だけど時間が無くなったので、今日はここまで。続きとしては、構文木を「交配」させたり「突然変異」させたりする方法を定義して、実際に「遺伝的プログラミング」を試してみる予定。
TCP/IPをマスタリングしたい
最近、ネットワークの事ちゃんと理解したいなーと思って、積読されてた「マスタリングTCP/IP」という本を読んでみた。TCP/IPを言いつつそれより下のレイヤーのイーサネットとか上のレイヤーのSMTPとかHTTPとかまで解説してくれてるので、親切な本だと思う。いろんなとこでオススメされてるし、良さげ。
とりあえず、内容をざっくりとまとめてみる。
ネットワークの階層構造
僕らは普段当然の様にネットワークを利用して様々な情報をやり取りしてる訳だけど、実はその背後には様々な複雑な仕組みがある。 例えば、僕らが最も頻繁に行うであろう「ブラウザを使用してのWebブラウジング」を考えてみても、HTTPのリクエストを送る為にまずTCPのコネクションを張る必要があって、TCPのコネクションを張る為にIPアドレスで宛先指定する必要があって、IPでパケット送るには物理層(LANケーブルとか光ファイバーとか無線とか)で繋がっててかつMACアドレスが割り振られたネットワークインターフェースを持ってる必要があって、って感じで階層下された沢山の仕組みを使って通信を行う事になる。 URLからIPアドレスを取得するにしてもDNSサーバにUDPで通信する必要があって、UDPはやっぱりIPやそれより下位のレイヤーに依存する事になる。
こういった階層化は一見複雑に見えるけど、むしろ適切な抽象化をもたらして全体の理解を容易にしてくれる。関心事を分離してレイヤー毎に自分の仕事に専念させる事で、上位のレイヤーからは下位のレイヤーのプロトコルの詳細を知らなくてもその役割だけを理解してれば良い事になる。一度に考える事を減らせるので、複雑性を減らす事が出来る。とっても良い。
TCP/IPとOSI参照モデル
ネットワークの階層はよく「OSI参照モデル」で説明される。
の7つの層から構成されてるとか言うやつ。下に行く程上位になっている。
これらは実際の実装との対応付けを行う事が出来て、例えば1の物理層はLANケーブルや無線みたいな物理的な送信路(と電気や電磁波による信号をビットに直す仕組み)に対応してる。2のデータリンク層は同じLAN内にある機器(PCやルータ)同士の、MACアドレス(ネットワークインターフェースに個別に割り振られた番号)を用いた通信に対応してる。3のネットワーク層が多くの人によっておそらく一番馴染みが深いIPを用いた通信に対応してて、IPアドレスによる宛先の指定なんかはこのレイヤーが責任を持っている。4のトランスポート層はTCPやUDPに対応してて、何をする為の通信なのか(サーバーへのHTTPリクエストなのかSSH通信なのかFTPによるファイル転送なのか)を管理してる。5~7はアプリケーションプログラムの責任としてひとまとめにされる。
マスタリングTCP/IPでは、これらの各レイヤーについて説明がなされてた。特に、IP(というかIPアドレス)については何となく知っててもデータリンク層やトランスポート層については意識しないとあんま触れる機会は無いと思うので、勉強する良いきっかけになった。
それぞれのレイヤーの詳細な説明は、機会があればまた後日する。だいぶ短くなっちゃったけど眠いので許して欲しい。
Go言語触ってみた その3
今週も、Goを触ってみて気になった点とかについてまとめてみる。
先週の振り返り
先週はGoの型システムについてブログを書いた。新しい型を定義する際に、
- 既存の型に別名(?)をつける場合
- struct型を定義する場合
- interface型を定義する場合
の3通りの方法があると述べた。
今週は、先週ちょろっと触れながら詳しくは説明しなかったembedding typeについて触れる。